
Data Centre Leaf-Spine Fabric
Modern data centers demand a fabric that operates as a seamless extension of the compute environment -- not an isolated appliance managed through a separate toolchain. VelOS DC delivers leaf-spine fabric architecture on enabling network engineers and compute teams to share the same Linux-native tools, automation frameworks, and operational workflows -- with seamless integration into existing compute infrastructure through open standards.
Linux-Native Data Centre Leaf-Spine Fabric Built for Scalable Infrastructure

About Evollabs
Evollabs Tech operates a next-generation data centre networking and leaf-spine fabric environment designed to support enterprises, cloud providers, and infrastructure teams in building scalable, high-performance network architectures. Built on deep telecom and IP networking expertise, our platform enables organizations to design, validate, and optimize unified compute and network operations using Linux-native tooling and open standards.
THE CHALLENGE
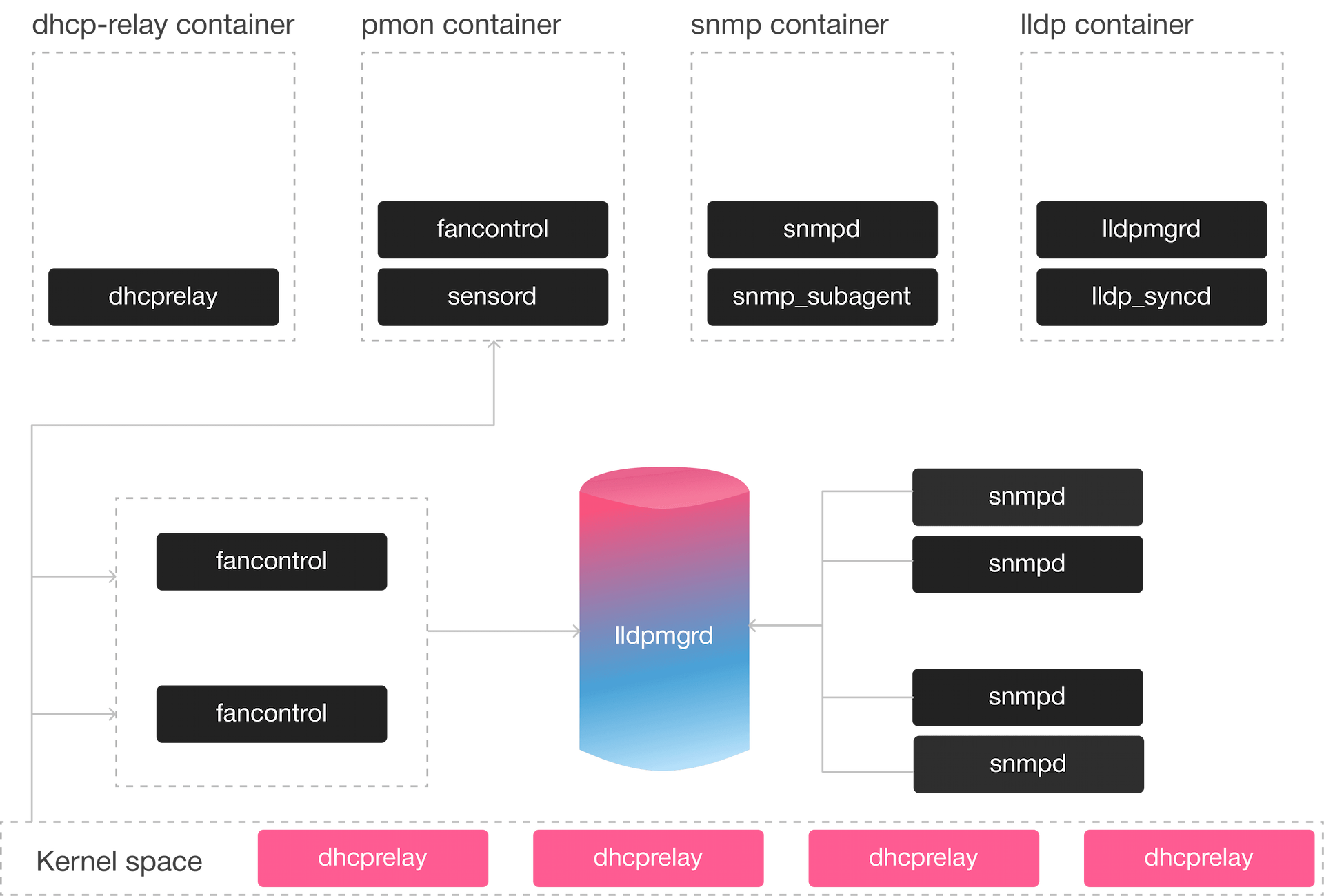
Data center operations are increasingly defined by the tools and workflows of the compute environment. Ansible orchestrates server deployments, Puppet manages configuration state, systemd governs service lifecycles, and shell scripts automate everything in between. Yet the network fabric that connects these compute resources remains a separate operational domain -- managed through proprietary command-line interfaces, governed by vendor-specific automation adapters, and staffed by specialists trained on platforms that share nothing with the Linux ecosystem surrounding them.
This operational divide creates real costs. Network changes require a different team, a different toolchain, and a different approval workflow than compute changes. Automation pipelines that provision a hundred servers in minutes stall when they reach the network layer, because the switches do not speak the same language as the rest of the infrastructure. Troubleshooting spans two worlds: Linux tools diagnose compute issues, proprietary CLI tools diagnose network issues, and correlating the two requires manual effort and domain-specific expertise on both sides.
Scaling compounds the problem. A single rack with a top-of-rack switch is manageable regardless of toolchain. But as data centers grow from tens of racks to hundreds -- from campus-level deployments to multi-site operations -- the operational overhead of maintaining a separate network management domain grows proportionally. And when the time comes to refresh hardware, proprietary vendors bundle their software with their switches: upgrading the NOS means replacing the hardware, and replacing the hardware means re-qualifying the entire fabric. The vendor lock-in that seemed manageable at rack scale becomes a strategic liability at data center scale.
THE SOLUTION
VelOS DC eliminates the divide between compute operations and network operations by making the data center fabric a native member of the Linux environment. The kernel is the source of truth for network state -- standard Linux networking commands (ip, bridge, tc) interact with the fabric directly. There is no proprietary abstraction layer between the operator and the network, and no translation required between compute automation and network configuration.
The fabric architecture is built on Border Gateway Protocol (BGP) for underlay routing and Ethernet Virtual Private Network (EVPN) with Virtual Extensible LAN (VXLAN) for overlay services. Equal-Cost Multi-Path (ECMP) routing distributes traffic across all available spine links, eliminating single points of congestion and maximising aggregate fabric bandwidth. Multi-Chassis Link Aggregation (MLAG) provides redundant server connectivity at the leaf layer, ensuring that no single link or switch failure disrupts compute workloads.
Every tool a Linux engineer already knows works natively on VelOS DC. Ansible playbooks configure switches the same way they configure servers. Puppet enforces configuration state across compute and network infrastructure simultaneously. Salt, shell scripts, cron jobs, and systemd manage network services without proprietary CLI wrappers. The result is a unified operational model where the same team, using the same tools and the same workflows, manages both compute and network infrastructure -- from a single rack to a hyperscale deployment.
RECOMMENDED HARDWARE
VelOS DC runs on Evollabs data center switches built on Broadcom switching silicon. The following hardware is recommended for leaf-spine fabric deployments, covering roles from cost-effective leaf switches to hyperscale spine switches.
| Role | Model | Ports | Chipset | Why This Hardware |
|---|---|---|---|---|
| Role Leaf (25G) | Model EVO-5030X-48Y | Ports 48x25G SFP28 + 8x100G QSFP28 | Chipset Broadcom Trident 3 | Why This Hardware Cost-effective leaf with high 25G density for server-facing ports and 100G uplinks to spine |
| Role Leaf/Spine (100G) | Model EVO-5030X-32C | Ports 32x100G QSFP28 | Chipset Broadcom Trident 3 | Why This Hardware Flexible 100G platform for leaf or spine roles in medium data centers |
| Role Spine (100G) | Model EVO-7020X-64C | Ports 64x100G QSFP28 | Chipset Broadcom Tomahawk 2 | Why This Hardware Medium-bandwidth spine, 6.4 Tbps class for spine roles in medium to large data centers |
| Role Spine (400G) | Model EVO-7030X-32F | Ports 32x400G QSFP-DD | Chipset Broadcom Tomahawk 3 | Why This Hardware High-bandwidth spine, 12.8 Tbps class, with 400G breakout to 4x 100G for flexible scaling |
| Role Spine (Hyperscale) | Model EVO-7040X-64F | Ports 64x400G QSFP-DD | Chipset Broadcom Tomahawk 4 | Why This Hardware Maximum radix and bandwidth, 25.6 Tbps class for hyperscale data center fabrics |
DEPLOYMENT TOPOLOGY
Data Center Leaf-Spine Fabric with VelOS DC
This topology features a scalable leaf-spine architecture using Evollabs switches with 25G and 100G leaf nodes interconnected to high-capacity 400G spine switches. It supports BGP underlay and EVPN-VXLAN overlay, enabling efficient east-west and north-south traffic flows. With ECMP and MLAG for redundancy, the design ensures high availability, performance, and seamless scalability up to large data center deployments.
USE CASE SCENARIOS
A mid-size enterprise operates a 200-rack data center running a mix of virtualised workloads and bare-metal compute. The existing network fabric uses proprietary switches with vendor-specific management tools, requiring a dedicated network operations team separate from the compute and DevOps teams.
Deployment: Replace proprietary leaf switches with (48x25G SFP28 for server connectivity, 8x 100G uplinks) and deploy as spine switches (32x400G QSFP-DD, broken out to 4x100G per port for leaf connectivity). VelOS DC enables the existing Linux-trained compute team to manage both servers and switches using Ansible playbooks and standard Linux tools -- eliminating the need for a separate network operations toolchain.
Result: Unified operations across compute and network. VelOS DC can even upgrades your network without hardware replacement as it runs on the industry-standard Broadcom silicon so it’s open to be adapted to any Broadcom-based silicon switch (it’s not by default, pls speak to your sales representative). Significant CapEx reduction through Evollabs hardware versus traditional vendor alternatives.
Capabilities
Key capabilities for data center leaf-spine fabric
VelOS DC is a data center network operating system built from the ground up on Linux -- not layered on top of it. It integrates natively with compute environments, automation frameworks, and data center fabrics, delivering hyperscaler-grade networking with seamless integration into existing infrastructure through open standards.
VelOS DC
The Linux-Native NOS for the AI-Ready Data Center

BGP underlay with ECMP
EVPN-VXLAN overlay
MLAG
Linux-native operations
Standard automation interfaces

Experience Performance at scale
Partner with Evollabs Tech to validate, optimize and scale your intelligent systems in the UAE’s most advanced computational testing environment.

Contact
Evollabs Tech FZ-LLC DIC-Bldg. 05-118, Dubai Internet City United Arab Emirates
© EVOLLABS, all rights reserved.
Developed by SpiderWorks